CTC-Loss
Voice Recognition Problem
Input: A recording, then will be processed into a Spectrogram
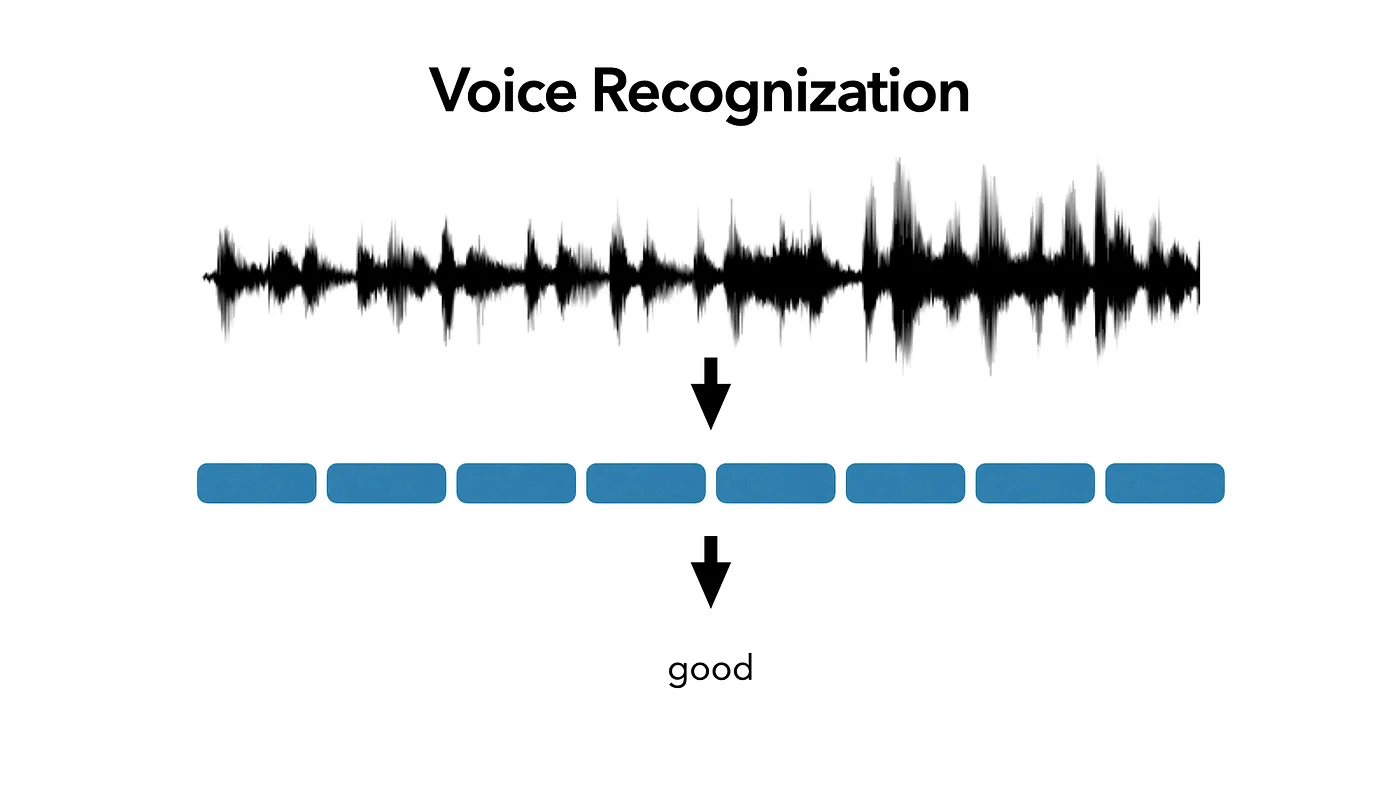
Output: The text based on the predicted result
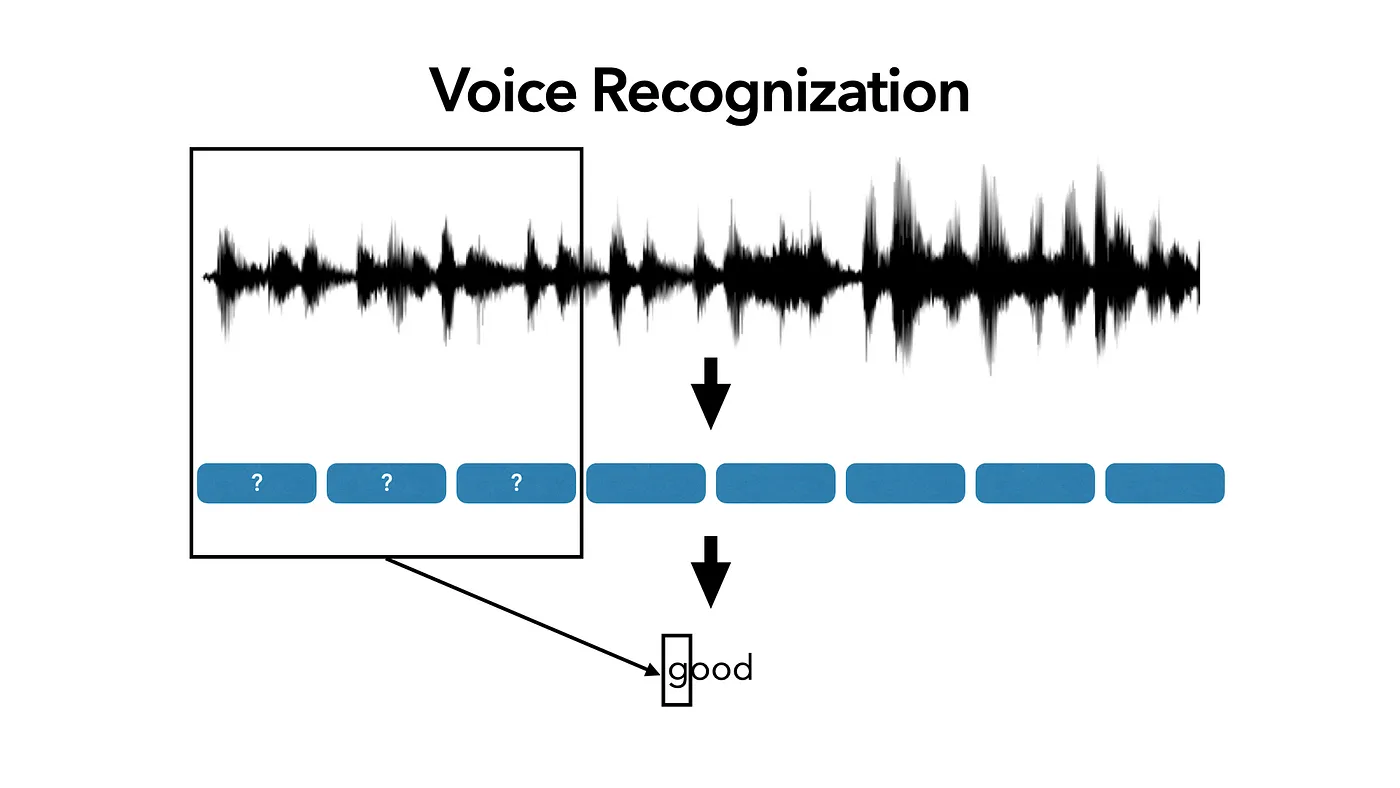
Difficulties:
- Only have recording and corresponding text ⇒ don’t have alignment for each character or word to its voice
- If we use the Loss that requires input and target correspond, we can not train model in this case ( due to the lack of alignment )
⇒ Idea of Connectionist Temporal Classification (CTC-Loss)
CTC-Loss
Properties must satisfies:
-
Allow repeated output: When the model is not sure at which moment it should output, it should allow model to predict the same token multiple times
-
Merge output: Merger these repetitive outputs.
- In order to distinguish between 2 consecutive tokens and duplicate tokens, we use ‘_’ to separate
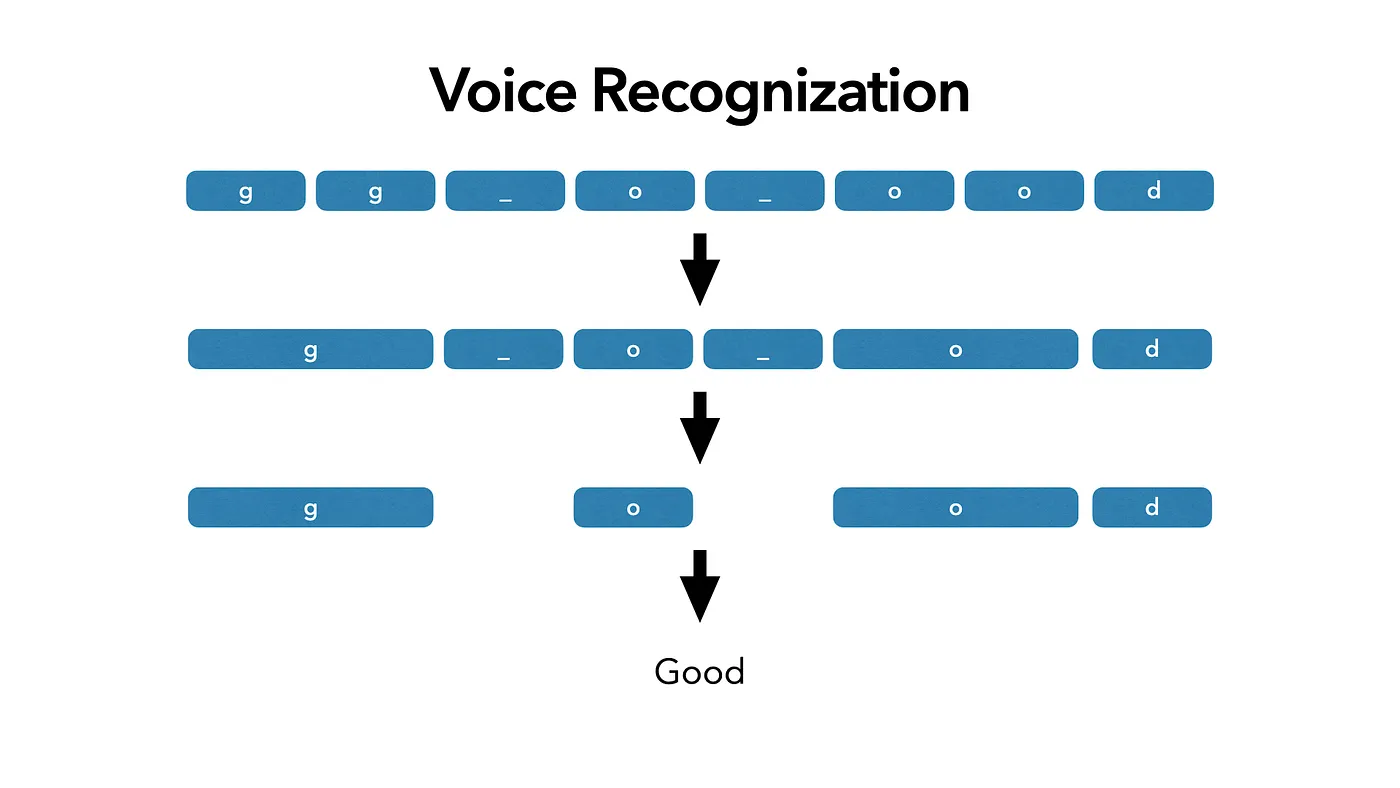
Example:
Input a piece of audio, and predict the word ‘g’. Assuming the model decodes 3 states, each give us the prob. of all tokens and we select the result with the highest prob.
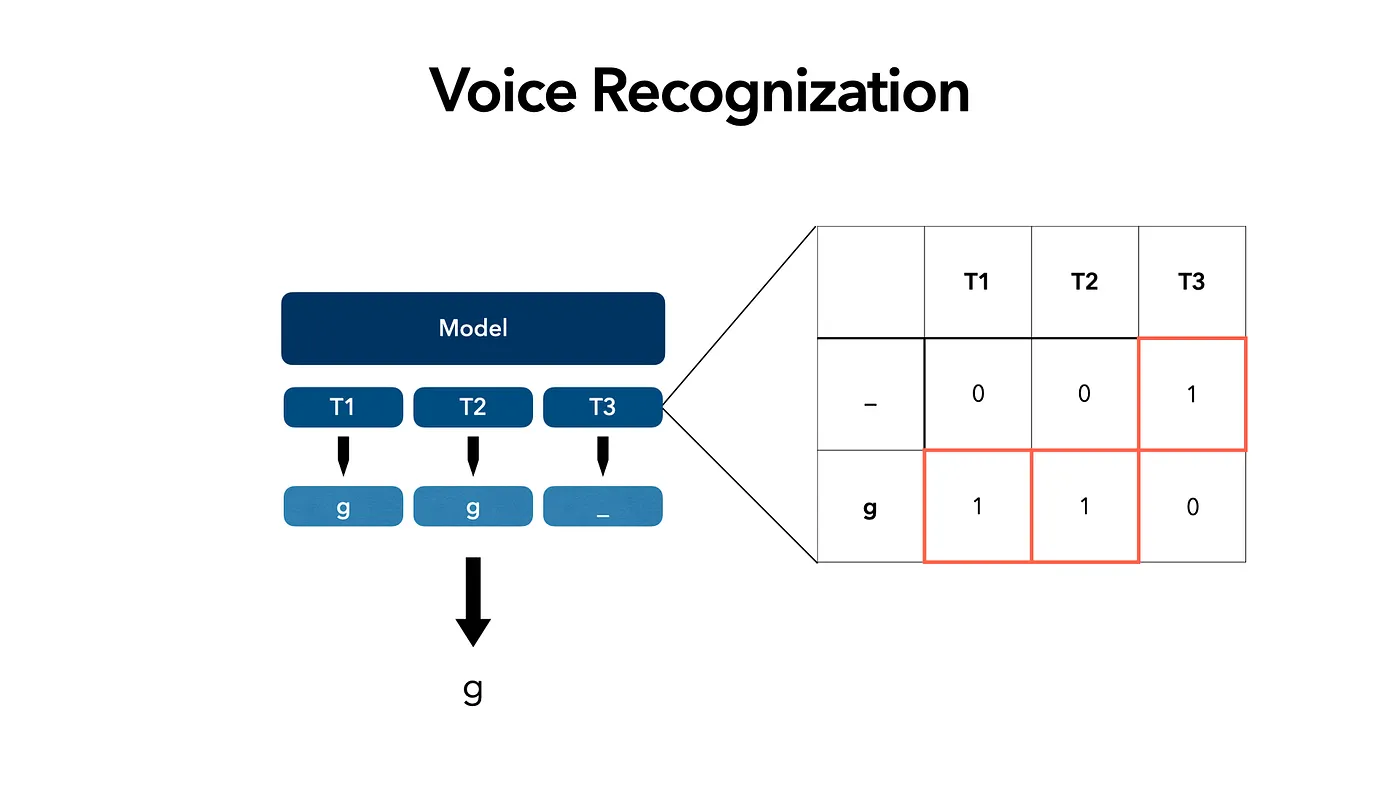
But there are many combinations (a.k.a the path to get the desired target) that can generate the same result, we need to guide the model to produce one of the results, then we can decode the corresponding text.
⇒ Enumerate all the combinations and calculate the loss for each. (Idea of CTC-Loss)
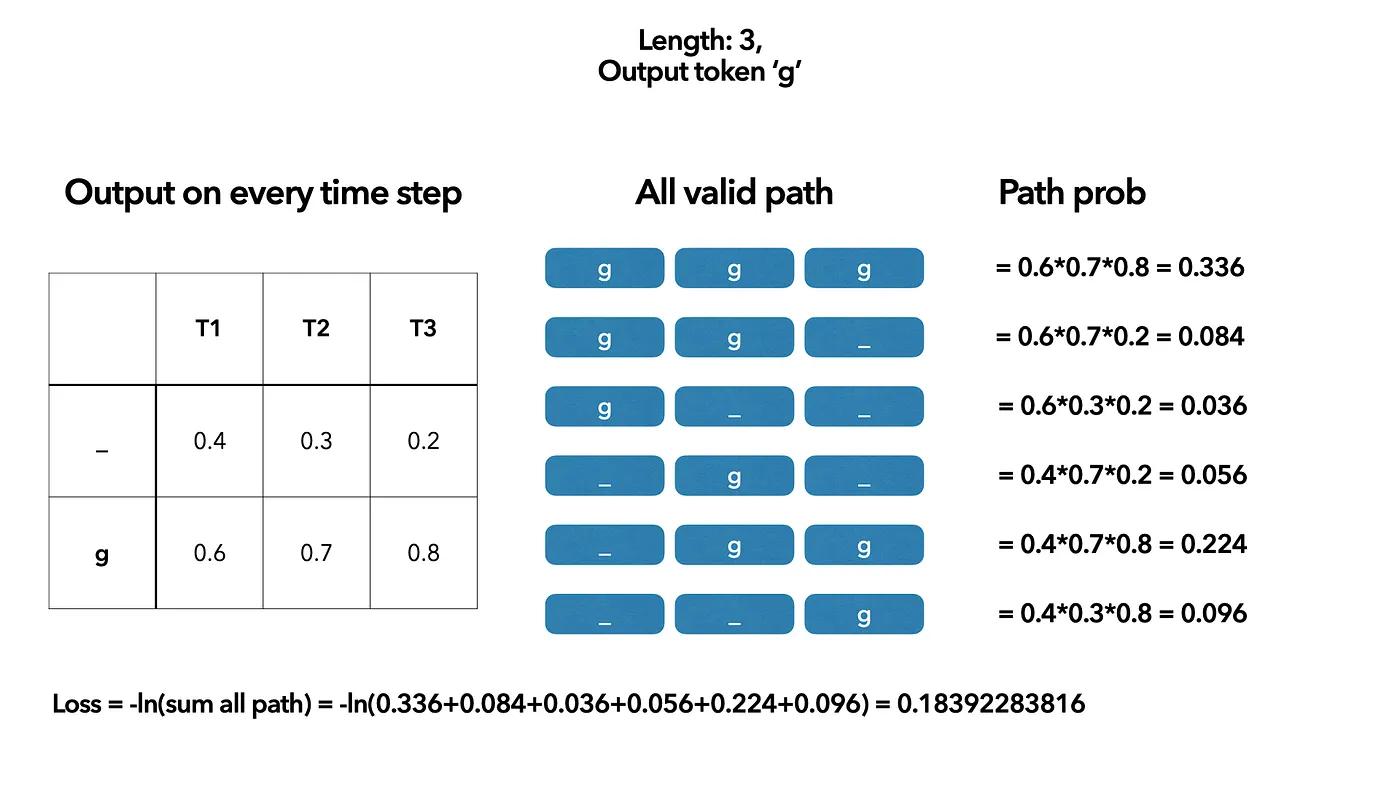
Disadvantages:
- The number of combinations increases exponentially as the length of the input increases ⇒ Too long to train a large amount of data.
⇒ To increase efficiency, we need to use Dynamic Programming. (quite similar to Viterbi algorithm)
Boosting performance using DP
Forward-backward Algorithm:
- First, list all prob. output on every timestep. Then create another table to simulate the DP calculation
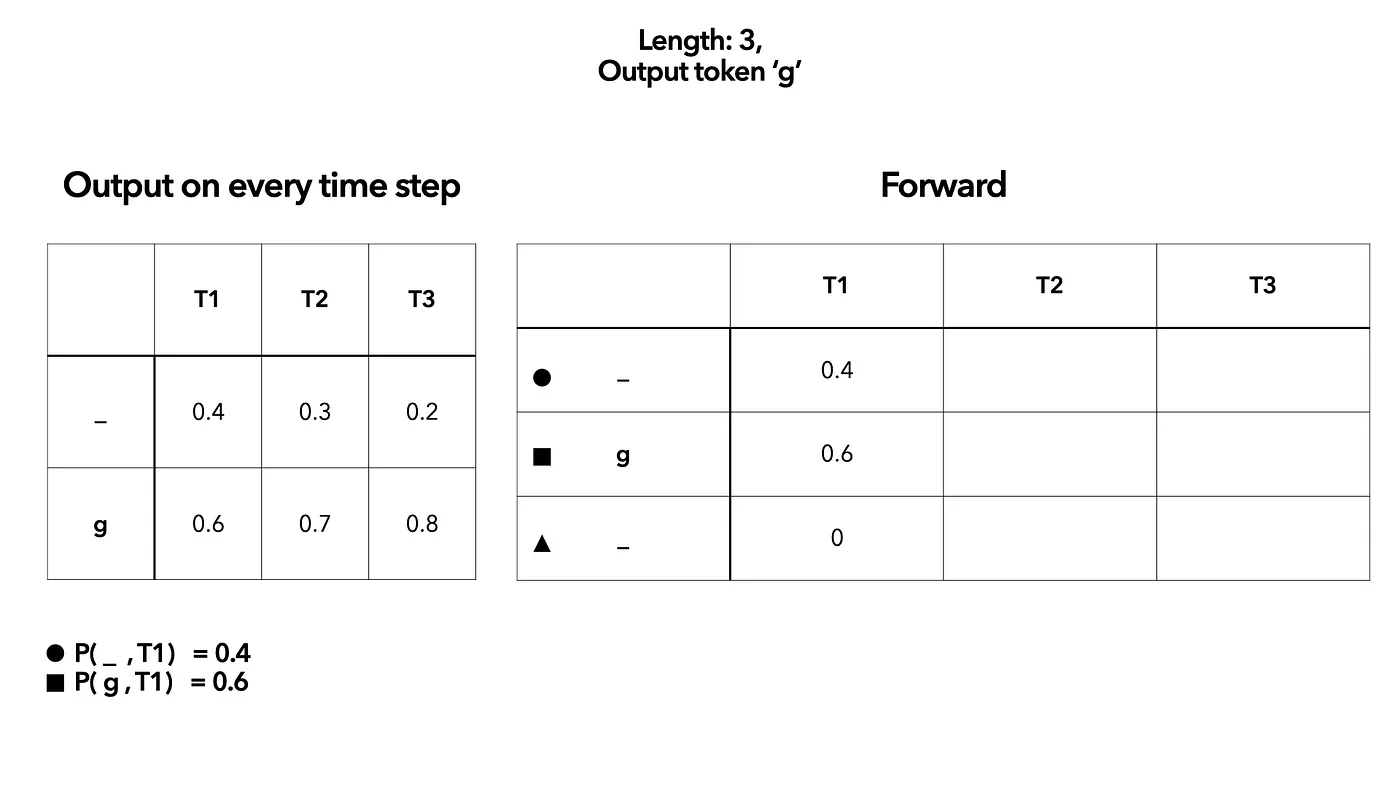
-
At the first time step $T_1$, we give each of the element corresponding probability from left. Remember that we have two “” here (one for start and one for end). We use circle and triangle to distinguish. The triangle “” prob. in $T_1$ is 0 because at time step $T_1$( which is the start point) we can not have end “_”.
-
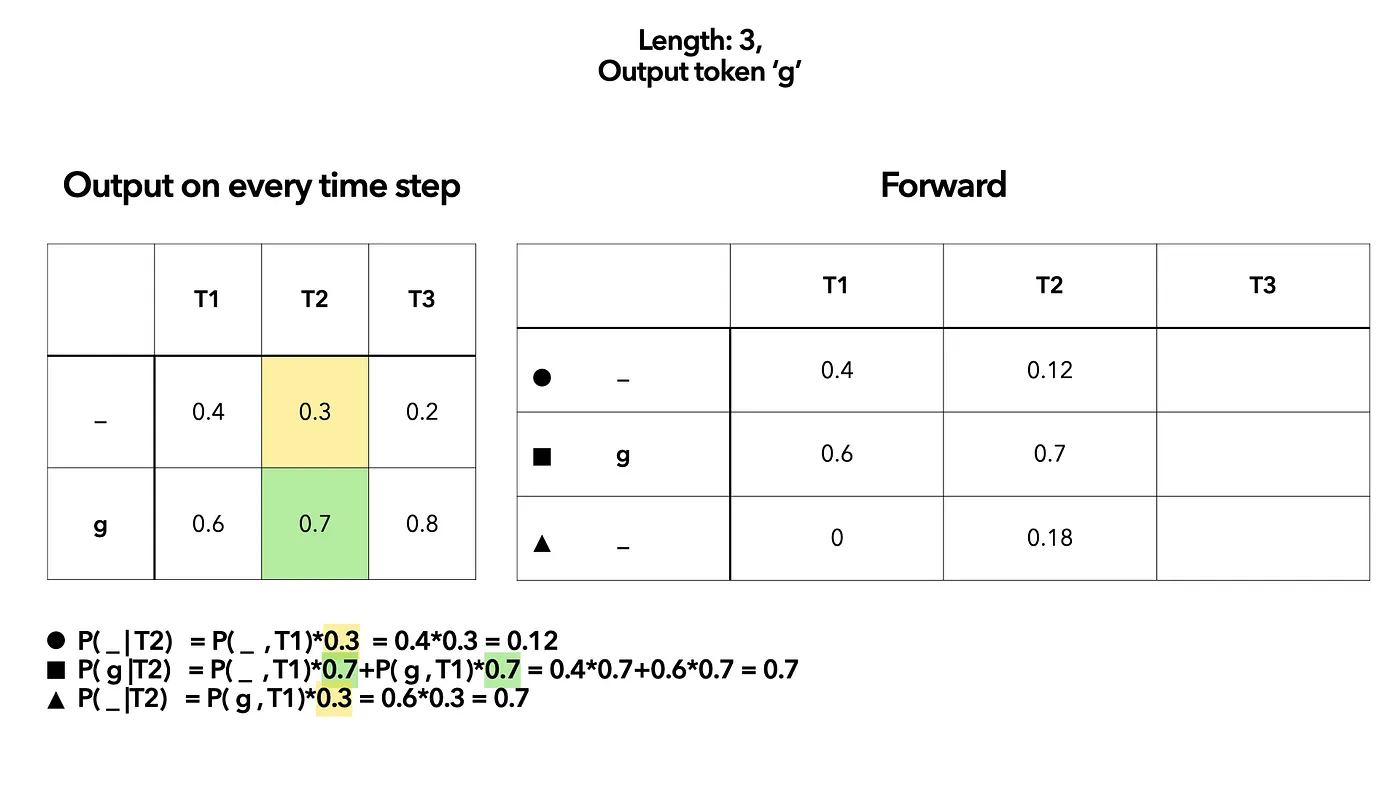
Then calculate $T_2$ based on the result of $T_1$.
(T2,
_circle) will only come from (T1,_circle).(T2,g) may come from (T1,
_circle) and (T1,g).(T2,
_, triangle) will be the result after (T1, g).
- Calculate $T_3$ similarly:
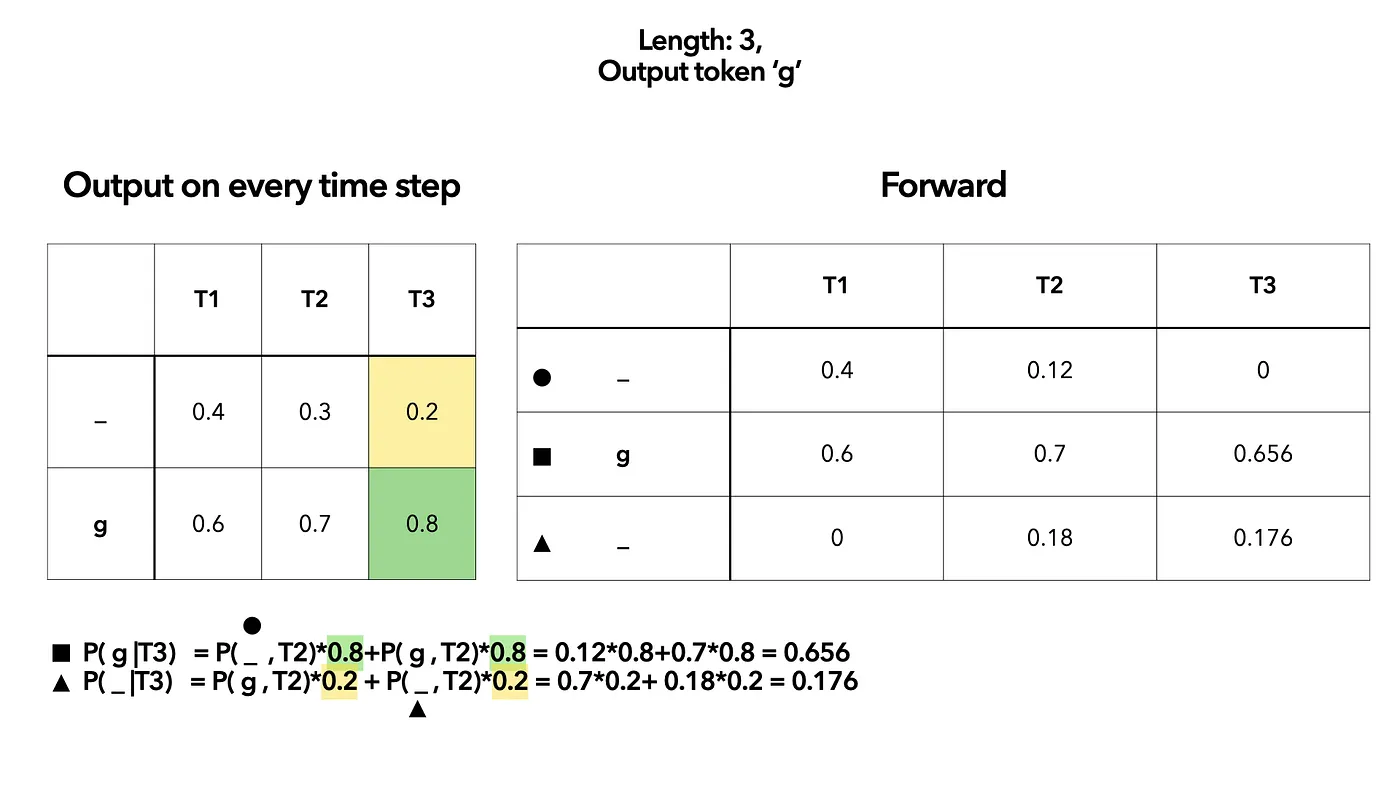
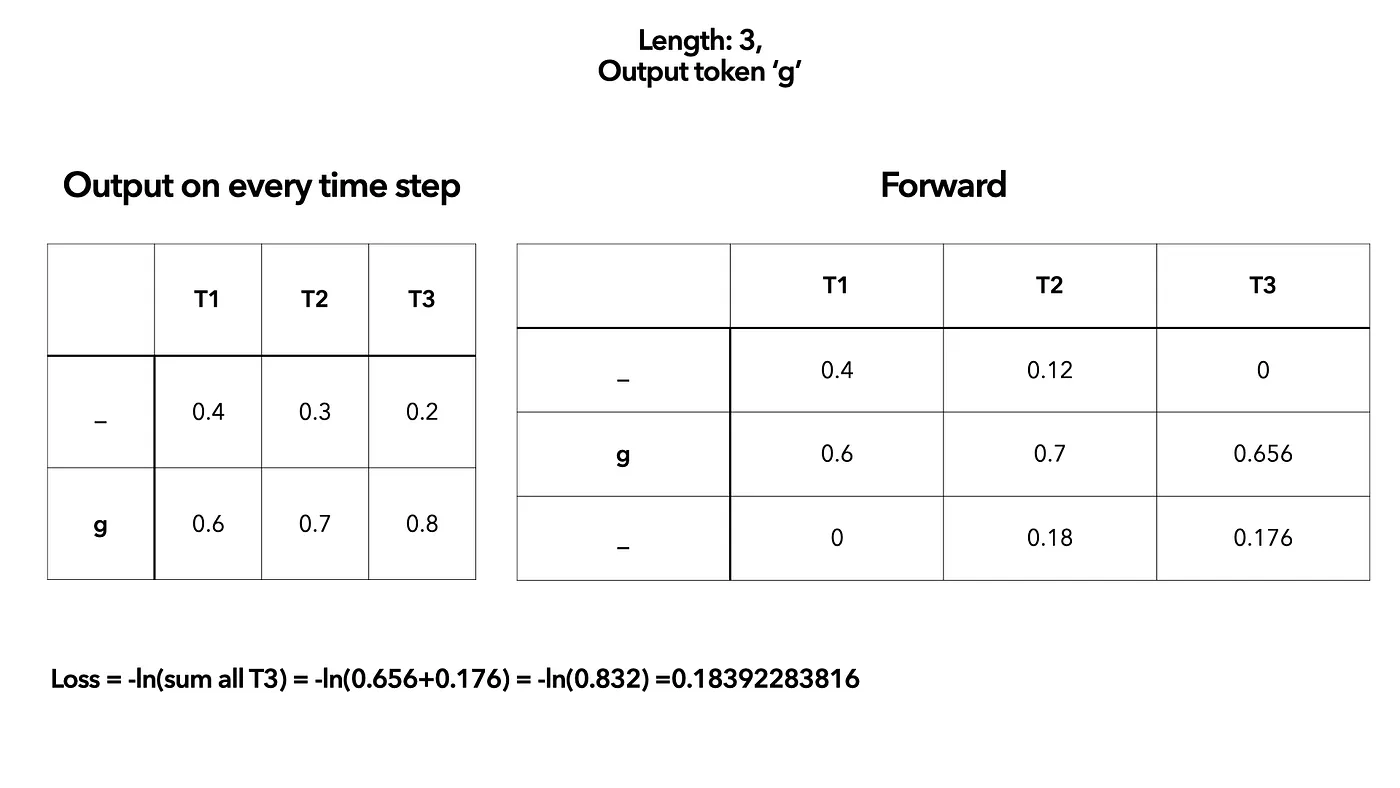
- Sum up the result and take log
Limitation:
The input length must larger than the output length. The longer input sequence, the harder to train.